【論文解説】Epiplexityとは?AIの情報理論を再定義する新概念
AIサマリー
Epiplexityは計算制約のあるAIモデルの学習可能性を定量化する新しい情報理論の尺度であり、シャノンエントロピーの限界を克服します。特に、データ拡張、カリキュラム学習、LLMの汎用能力など、従来の理論では説明できなかった現象を統一的に解決します。Epiplexityは、データセット設計や事前学習の最適化に新たな指針を提供し、今後のAI研究において重要な概念とされています。
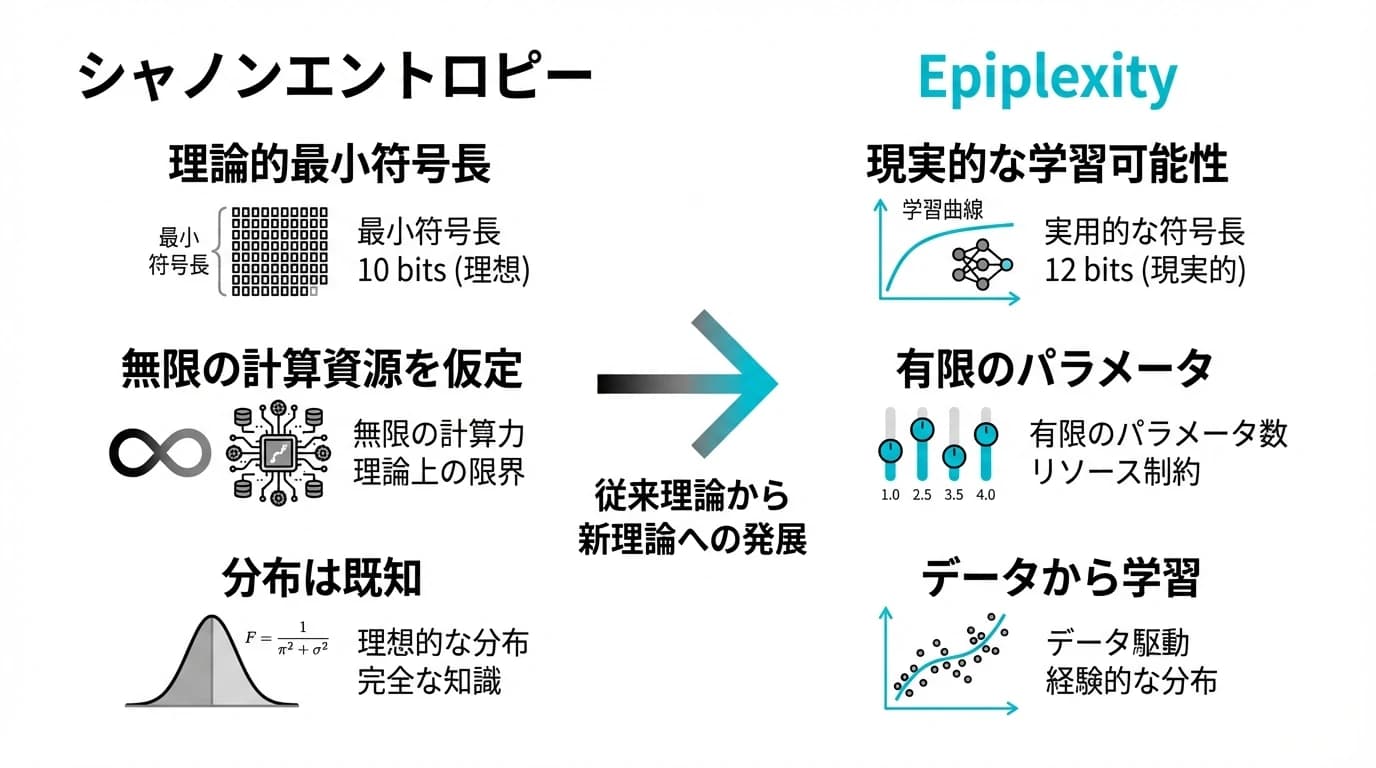
シャノンエントロピーは情報理論の基盤です。しかし、現実のAIモデルには「無限の計算資源」がありません。
2026年にCMUとNYUの研究チームが発表した「Epiplexity(エピプレキシティ)」は、計算制約のあるモデルにとって何が学習可能かを定量化する新しい情報理論の尺度です。
本記事では、Epiplexity論文の内容を徹底解説します。従来の情報理論では説明できなかった3つのパラドックスをどう解決するかを明らかにします。
本記事の表記について
- 下線付きの用語にカーソルを合わせると解説が表示されます
- 情報理論の基礎知識がある方向けの上級記事です
この記事でわかること
- Epiplexityの基本概念: 計算制約のあるAIモデルにとって「何が学習可能か」を定量化する情報理論の尺度
- 3つのパラドックスの解決: Data Augmentation(データ拡張)、Curriculum Learning(カリキュラム学習)、LLMの汎用能力を統一的に説明
- 実践への示唆: データセット設計と事前学習の最適化に向けた指針
基本情報
| 項目 | 内容 |
|---|---|
| トピック | Epiplexity(情報理論) |
| カテゴリ | 論文解説 |
| 難易度 | 上級 |
| 発表 | arXiv 2026年1月(CMU, NYU) |
| arXiv | 2601.03220 |
従来の情報理論の限界
シャノンエントロピーの前提
クロード・シャノンが1948年に提唱した情報理論は、理想的な符号化に基づいています。
H(X) = -Σ p(x) log p(x)
この数式は「データ X を完全に記述するために必要な最小ビット数」を表します(符号長と呼ばれます)。
しかし、シャノンエントロピーには重大な前提があります:
- 分布 p(x) が既知である
- 最適な符号を構築できる無限の計算資源がある
- 復号にも無限の計算資源がある
現実のAIモデルとのギャップ
実際のAIモデル(GPT、BERT、ResNetなど)には厳しい計算制約があります。
| 理論の仮定 | 現実のAIモデル |
|---|---|
| 無限の計算資源 | 有限のパラメータ数 |
| 最適な符号化 | 勾配降下法(段階的な最適化)による近似 |
| 分布は既知 | データから学習(分布は未知) |
この乖離が、従来の情報理論では説明できない現象を生み出しています。
Epiplexityが解く3つのパラドックス
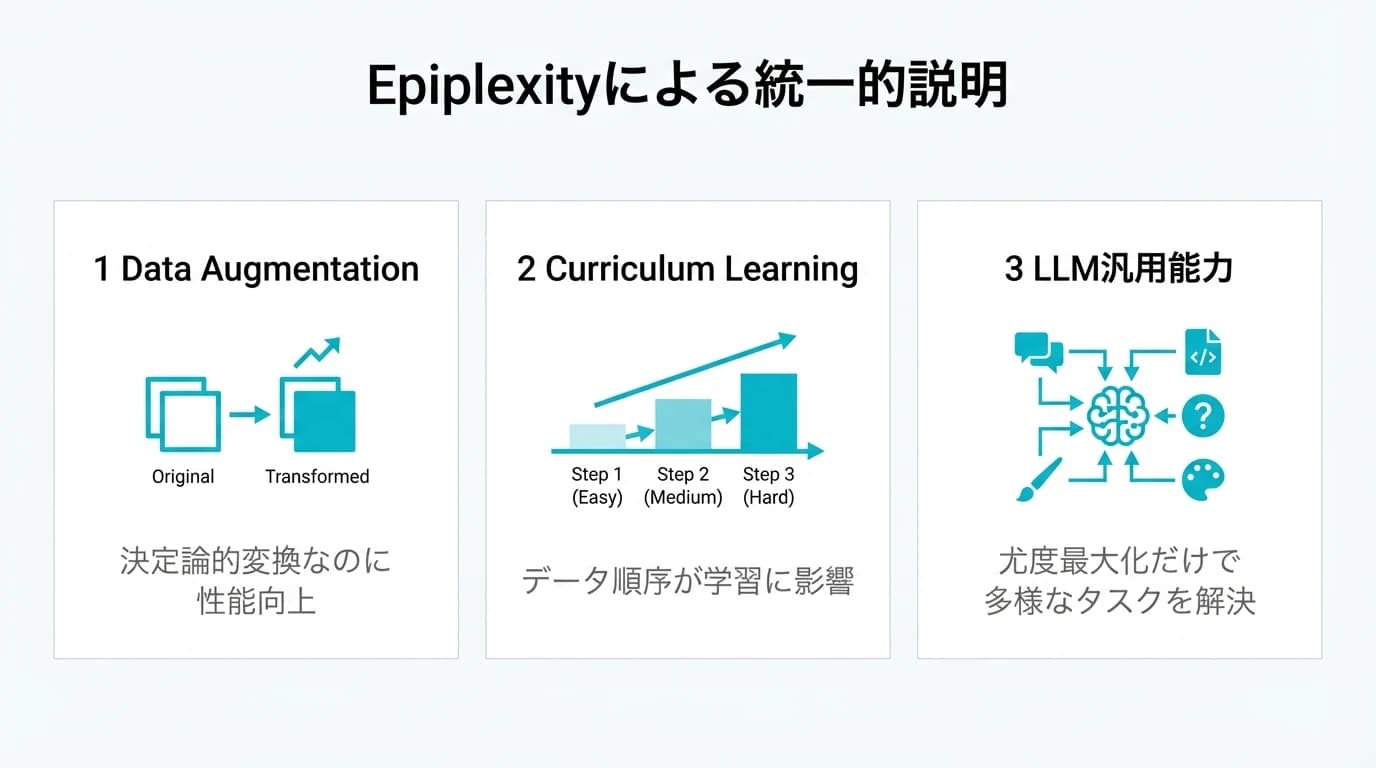
パラドックス1: 決定論的変換で情報が増加する
Data Augmentation(データ拡張) は、画像を回転・反転・ノイズ付加することでモデルの精度を向上させる技術です。
元画像 → 回転・反転・ノイズ付加 → 拡張データ → モデル精度向上
従来の情報理論の説明
決定論的変換では情報量は変化しません(むしろ減少)。数式では H(f(X)) ≤ H(X) となります。
現実
Data Augmentationでモデル性能が大幅に向上します。
Epiplexityの説明
変換によって「計算制約のあるモデルが学習可能な側面」が増加します。同じ情報量でも、モデルが利用しやすい形式に変換されているためです。
パラドックス2: データの順序が重要になる
Curriculum Learning(カリキュラム学習) は、簡単なデータから難しいデータへと学習順序を工夫する技術です。
簡単 → 普通 → 難しい → 高効率な学習
従来の情報理論の説明
データ集合の情報量は順序に依存しません。
現実
学習順序によって最終的なモデル性能が大きく変わります。
Epiplexityの説明
SGD(確率的勾配降下法) を使うモデルにとって、データの順序は「いつ・どの情報を吸収できるか」に影響します。Epiplexityはこの順序依存性を捉えます。
パラドックス3: 尤度モデリングは分布マッチング以上
LLMの事前学習は、次のトークンを予測する(尤度を最大化する)だけです。しかし、分類・生成・推論など多様なタスクで高性能を発揮します。
事前学習(尤度最大化) → 分類/生成/推論など複数の下流タスクで高性能
従来の情報理論の説明
尤度モデリングは単に学習データの分布を再現しているだけです。
現実
LLMは学習データに含まれない新しいタスクも解けます(ゼロショット能力)。
Epiplexityの説明
モデルは単なる分布マッチングではなく、構造的なパターンを学習しています。Epiplexityは、この「構造化された学習」を正しく評価します。
Epiplexityの定義
Prequential Coding
Epiplexityの中核はPrequential Coding(予測的逐次符号化) という符号化方式です。これは、データをオンラインで圧縮しながら学習する手法です。
def prequential_codelength(data, model, learning_algorithm):
"""
データをオンラインで圧縮しながら学習する
"""
total_codelength = 0
for i, x_i in enumerate(data):
# 現在のモデルでx_iを予測
prob = model.predict_probability(x_i)
codelength = -log(prob)
total_codelength += codelength
# モデルを更新
model = learning_algorithm.update(model, x_i)
return total_codelength
この符号長の期待値がEpiplexityです。
数式定義
データ分布 P、モデルアーキテクチャ M、学習アルゴリズム A に対して、Epiplexityは次のように定義されます:
Epiplexity(P | M, A) = E[Σ -log p_θ_t(x_{t+1})]
ここで θ_t は、データ x_1, ..., x_t を学習した後のモデルパラメータです。
エントロピーとの関係
| 尺度 | 何を測るか | 計算資源の仮定 |
|---|---|---|
| エントロピー | 理論的な最小符号長 | 無限 |
| Epiplexity | 特定のモデルが達成できる符号長 | 有限(現実的) |
重要な性質:Epiplexity ≥ Entropy
どんなモデル・アルゴリズムを使っても、シャノンエントロピー以下にはなりません。
実験結果と実用性
データ選択への応用
論文では、Epiplexityを使ったデータ選択が下流タスクの性能と強く相関することを示しています。
実験設定:
- 様々なデータセットに対してEpiplexityを計算
- 同じデータセットで学習したモデルの下流タスク性能を測定
- Epiplexityと性能の相関を分析
結果:
Epiplexityが低い(効率的に学習できる)データセットほど、下流タスクでの性能が高い傾向が確認されました。
OOD汎化との関係
EpiplexityはOOD汎化(Out-of-Distribution汎化) とも関連します。OOD汎化とは、学習時に見たことがないデータ分布に対しても高い性能を発揮する能力です。
以下のメカニズムが働きます:
- Epiplexityが低いデータで学習 → 構造的パターンを効率的に学習
- 構造的パターンは新しいドメインでも有効 → 汎用性が高い
- 結果としてOOD性能が向上 → 未知データへの対応力が高まる
AI開発への示唆
データセット設計の新しい指針
Epiplexityの観点から、良いデータセットは以下の特徴を持ちます:
- モデルが学習しやすい形式: 生データより前処理・拡張されたデータが効果的
- 適切な順序: 簡単から難しいへのカリキュラム構造を持つ
- 構造的多様性: 単なる量より、学習可能なパターンの多様性が重要
事前学習の最適化
LLMの事前学習において、Epiplexityは以下の最適化に活用できます:
- データミックス比率の決定: どのデータをどの割合で混ぜるか
- 学習順序(カリキュラム)の設計: どの順番でデータを学習させるか
- データ品質の評価指標: データセットの良し悪しを定量評価
今後の研究方向
以下の研究テーマが期待されています:
- 大規模言語モデルでのEpiplexity計算の効率化: 現状は計算コストが高い
- Epiplexityに基づくデータ選択アルゴリズムの開発: 自動でデータを選別
- 他のアーキテクチャへの適用: Vision Transformerなど画像モデルへの応用
FAQ
Q1. Epiplexityは実際に計算できますか?
はい、Prequential Codingに基づいて計算可能です。
ただし、大規模なデータセット・モデルでは計算コストが高くなります。論文では効率的な近似手法も提案されています。
Q2. エントロピーはもう使わない方がいいですか?
いいえ、エントロピーは依然として重要です。
エントロピーは理論的下限を与える基礎的な指標です。Epiplexityは「実用的な学習可能性」を評価する補完的な指標として使うのが適切です。
Q3. Data Augmentationの効果を予測できますか?
理論的には可能です。
変換前後のEpiplexityを比較することで、その変換がモデルの学習にどう影響するかを予測できる可能性があります。
Q4. 日本語LLMにも適用できますか?
はい、適用可能です。
Epiplexityは言語に依存しない一般的な枠組みです。日本語データセットの評価にも使えます。
Q5. Epiplexityを使ったデータセット選定の具体例はありますか?
論文では、同じモデルで複数のデータセットを評価しています。
Epiplexityが低い(効率的に学習できる)データセットほど、下流タスクの性能が高くなることが示されています。事前学習データの選定や、ファインチューニングデータの品質評価に応用できます。
まとめ
Epiplexityは、計算制約のあるAIモデルにとって何が学習可能かを定量化する新しい情報理論の尺度です。
主要ポイント
- シャノンエントロピーの限界を克服: 無限の計算資源を仮定しない、現実的な評価指標を提供
- 3つのパラドックスを統一的に解決: Data Augmentation、Curriculum Learning、LLMの汎用能力を説明可能に
- データセット設計の新指針: データの「量」より「学習しやすさ」が重要であることを示す
次のステップ
本記事の内容を活用するための具体的なアクションです:
- Prequential Codingの概念を理解する: 自社データセットの評価に応用
- Curriculum Learningを検討する: 学習パイプラインに取り入れる
- 関連研究との接続を深める: Data Augmentation、OOD汎化などを調査
関連記事
参考リソース
本記事はネクサフローのAI研究シリーズの一部です。
この記事の著者

中村 知良
代表取締役
早稲田大学卒業後、ソフトバンク株式会社にてAI活用やCEO直下案件のプロジェクトマネージャーに従事。その後、不動産スタートアップPit in株式会社の創業、他スタートアップでの業務改善・データ活用を経験後、2023年10月、株式会社ネクサフローを創業し代表取締役CEO就任。


